Anomaly detection for RPi monitoring
Learn how to use a low-overhead machine learning algorithm alongside Netdata to detect anomalous metrics on a Raspberry Pi.
We love IoT and edge at Netdata, we also love machine learning. Even better if we can combine the two to ease the pain of monitoring increasingly complex systems.
We recently explored what might be involved in enabling our Python-based anomalies collector on a Raspberry Pi. To our delight, it's actually quite straightforward!
Read on to learn all the steps and enable unsupervised anomaly detection on your on Raspberry Pi(s).
Spoiler: It's just a couple of extra commands that will make you feel like a pro.
What you need to get started
- A Raspberry Pi running Raspbian, which we'll call a node.
- The open-source Netdata monitoring agent. If you don't have it installed on your node yet, get started now.
Install dependencies
First make sure Netdata is using Python 3 when it runs Python-based data collectors.
Next, open netdata.conf using edit-config
from within the Netdata config directory. Scroll down to the
[plugin:python.d] section to pass in the -ppython3 command option.
[plugin:python.d]
# update every = 1
command options = -ppython3
Next, install some of the underlying libraries used by the Python packages the collector depends upon.
sudo apt install llvm-9 libatlas3-base libgfortran5 libatlas-base-dev
Now you're ready to install the Python packages used by the collector itself. First, become the netdata user.
sudo su -s /bin/bash netdata
Then pass in the location to find llvm as an environment variable for pip3.
LLVM_CONFIG=llvm-config-9 pip3 install --user llvmlite numpy==1.20.1 netdata-pandas==0.0.38 numba==0.50.1 scikit-learn==0.23.2 pyod==0.8.3
Enable the anomalies collector
Now you're ready to enable the collector and restart Netdata.
sudo ./edit-config python.d.conf
# restart netdata
sudo systemctl restart netdata
And that should be it! Wait a minute or two, refresh your Netdata dashboard, you should see the default anomalies charts under the Anomalies section in the dashboard's menu.
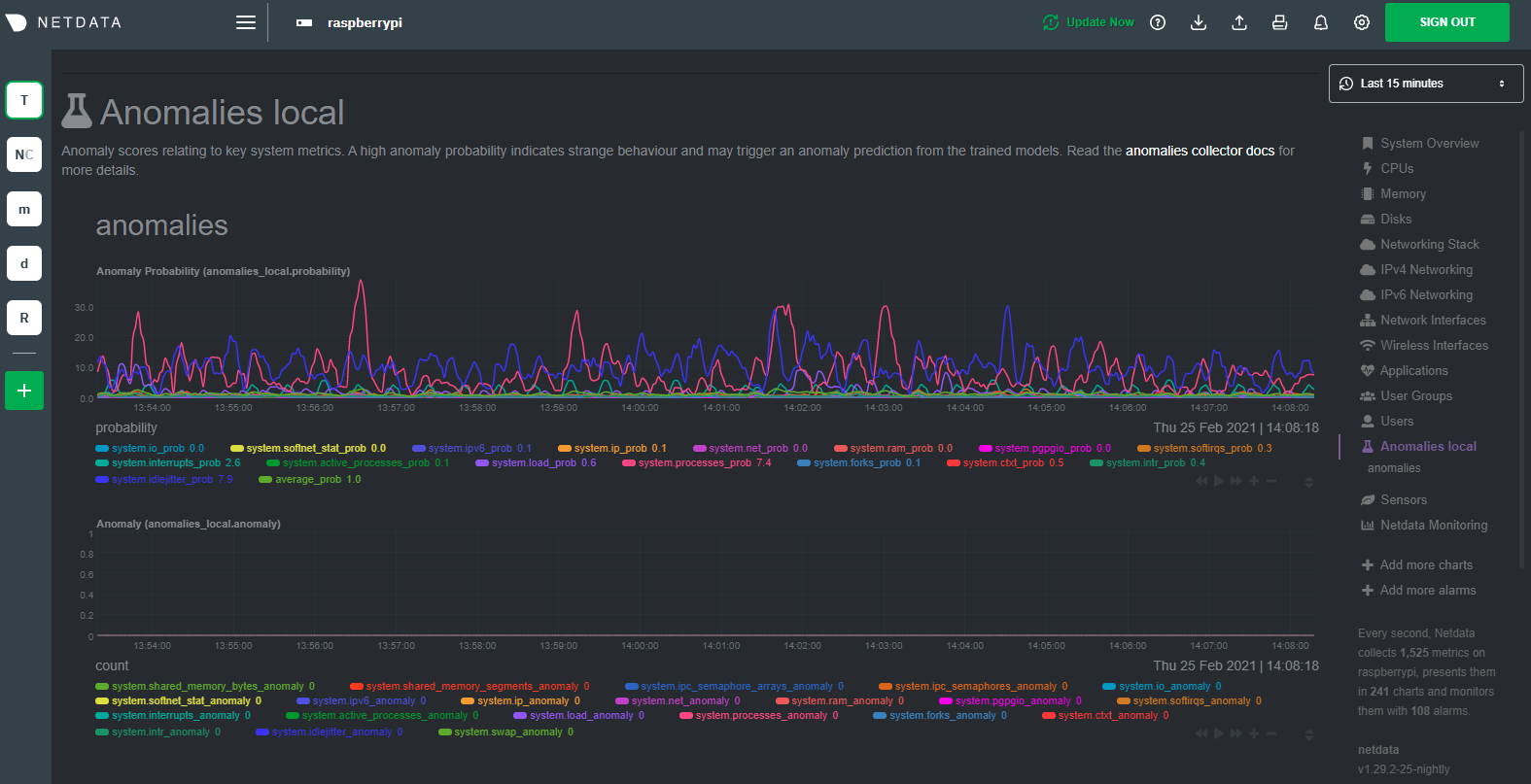
Overhead on system
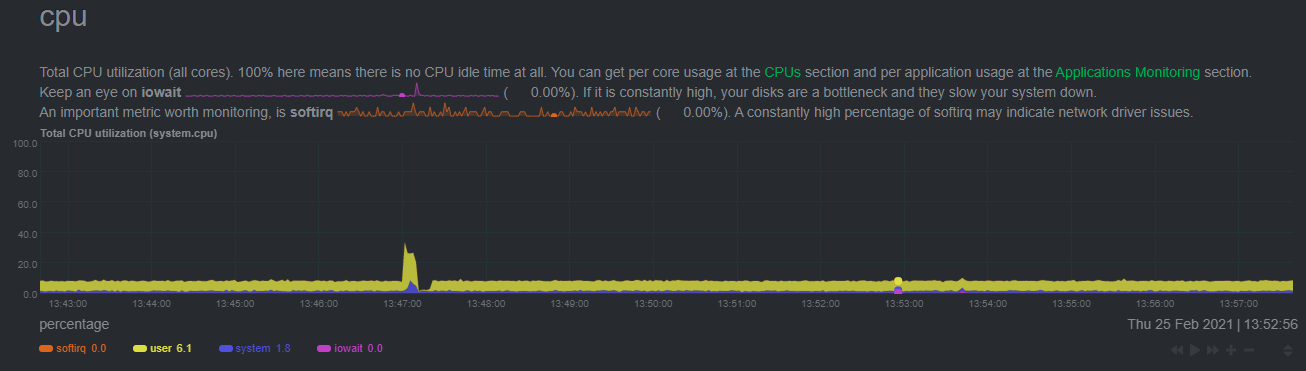
Of course one of the most important considerations when trying to do anomaly detection at the edge (as opposed to in a centralized cloud somewhere) is the resource utilization impact of running a monitoring tool.
With the default configuration, the anomalies collector uses about 6.5% of CPU at each run. During the retraining step, CPU utilization jumps to between 20-30% for a few seconds, but you can configure retraining to happen less often if you wish.
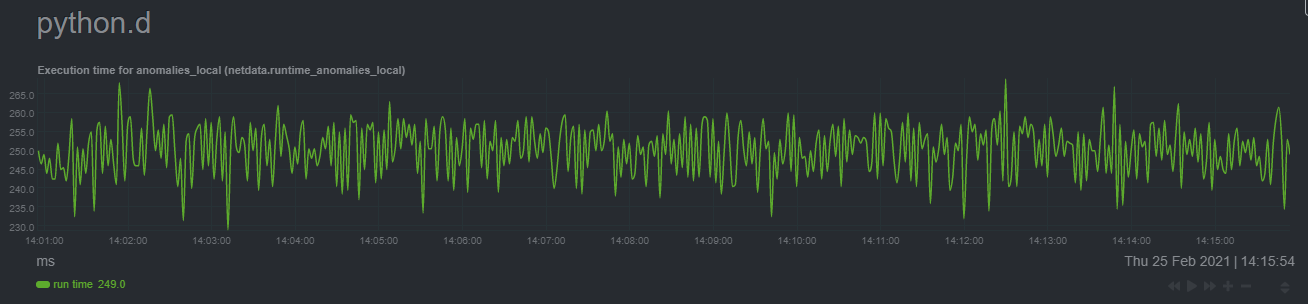
In terms of the runtime of the collector, it was averaging around 250ms during each prediction step, jumping to about 8-10 seconds during a retraining step. This jump equates only to a small gap in the anomaly charts for a few seconds.
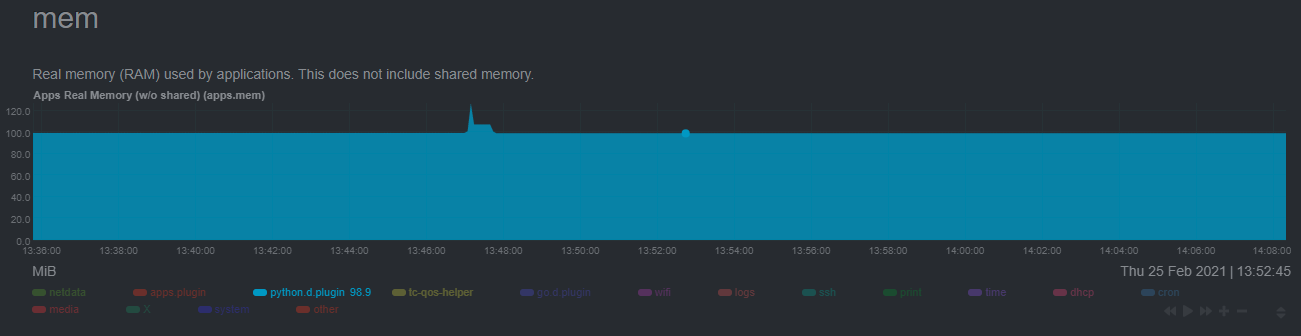
The last consideration then is the amount of RAM the collector needs to store both the models and some of the data during training. By default, the anomalies collector, along with all other running Python-based collectors, uses about 100MB of system memory.
Do you have any feedback for this page? If so, you can open a new issue on our netdata/learn repository.