Custom Investigations
Create deeply researched, context‑aware analyses by asking Netdata open‑ended questions about your infrastructure. Custom Investigations correlate metrics, anomalies, and events to answer the questions dashboards can’t—typically in about two minutes.
When to use Custom Investigations
- Troubleshoot complex incidents by delegating parallel investigations
- Analyze deployment or configuration change impact (before/after)
- Optimize performance and cost (identify underutilization and hotspots)
- Explore longer‑term behavioral changes and trends
Start an investigation
Two ways to launch:
- From anywhere: Click
Troubleshoot with AI(top‑right). The current view’s scope (chart, dashboard, room, service) is captured automatically; add your question and context. - From Insights: Go to
Insights→New Investigationfor a blank canvas and full control.
Reports are saved in Insights and you’ll receive an email when ready.
Provide good context (get great results)
Think of this as briefing a teammate. Include time ranges, environments, related services, symptoms, and recent changes.
Example 1: Troubleshooting a problem
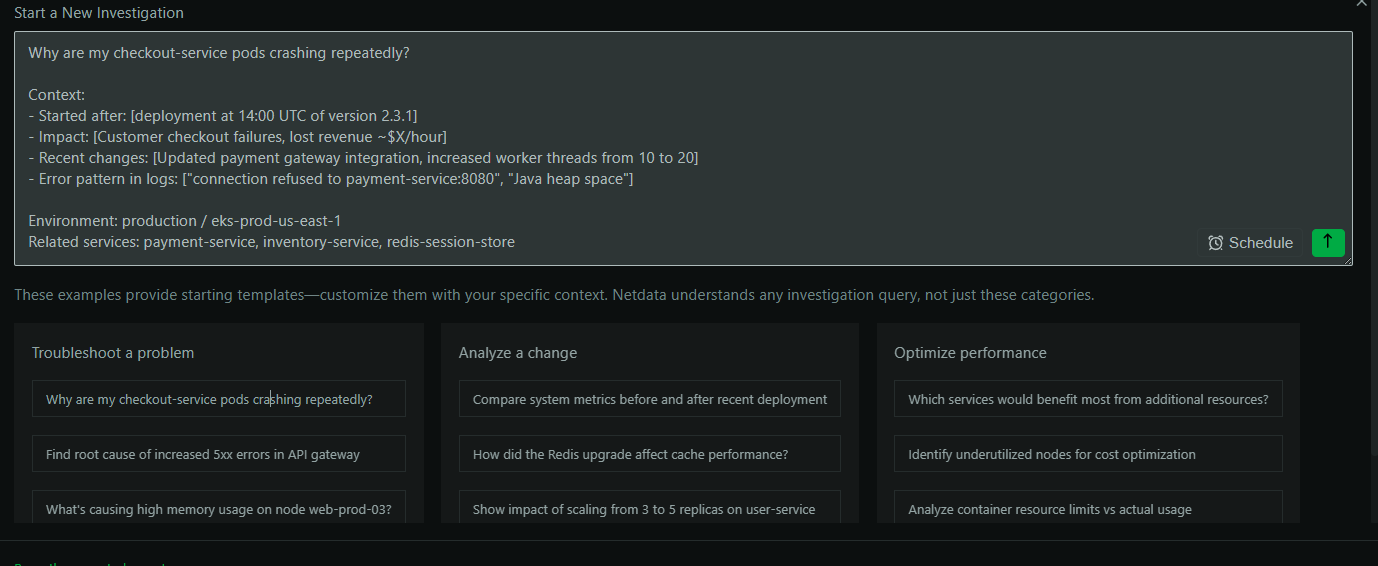
Request: Why are my checkout‑service pods crashing repeatedly?
Context:
- Started after: deployment at 14:00 UTC of version 2.3.1
- Impact: Customer checkout failures, lost revenue ~$X/hour
- Recent changes: payment gateway integration update; workers 10→20
- Logs: "connection refused to payment-service:8080", "Java heap space"
- Environment: production / eks-prod-us-east-1
- Related: payment-service, inventory-service, redis-session-store
Example 2: Analyze a change
Request: Compare system metrics before and after the user‑authentication‑service deployment.
Context:
- Service: user-authentication-service v2.2.0
- Deployed: 2025‑01‑24 09:00 UTC
- Changes: JWT→Redis sessions; Argon2 hashing
- Concern: intermittent logouts; rising redis_connected_clients
- Windows: 24h before vs 24h after
Example 3: Cost optimization
Request: Identify underutilized nodes for cost optimization.
Context:
- Monthly compute: ~$12K
- Mixed workloads (prod + staging)
- Dev envs run 24/7; batch nodes idle 20h/day
- Goal: save $2–3K/month without reliability impact
Best practices
- Be specific: timeframe, environment, services
- Add helpful context from tickets/Slack/deploy logs
- Set clear goals (reduce costs, find root cause, etc.)
- Run multiple investigations in parallel during incidents
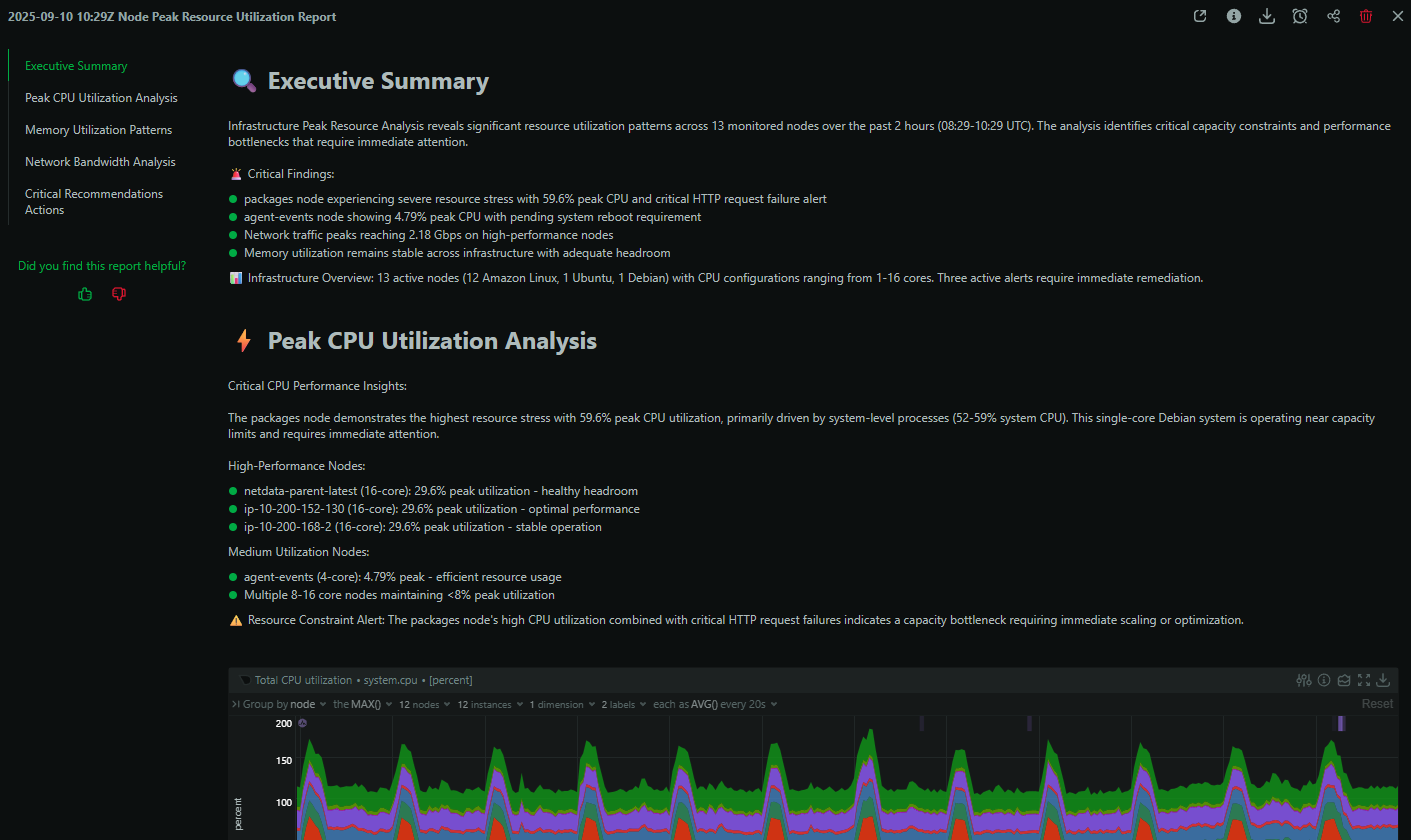
Scheduling
Automate recurring investigations (weekly health, monthly optimization, SLO conformance) from the Insights tab. See Scheduled Investigations for examples and setup.
Availability and credits
- Generally available in Netdata Cloud (Business and Free Trial)
- Eligible Spaces receive 10 free AI runs per month; additional usage via AI Credits
- Track usage in
Settings → Usage & Billing → AI Credits
Related
InvestigationsoverviewScheduled InvestigationsAlert Troubleshooting
Do you have any feedback for this page? If so, you can open a new issue on our netdata/learn repository.